
티스토리 뷰
문제
"이진 트리의 오른쪽 측면 뷰"
문제의 내용을 간단히 설명하자면:
이진 트리가 주어졌을 때, 오른쪽에서 트리를 바라본다고 가정했을 때 보이는 노드들의 값을 순서대로 반환하는 문제입니다. 즉, 각 레벨에서 가장 오른쪽에 있는 노드의 값을 찾아 리스트로 반환해야 합니다.
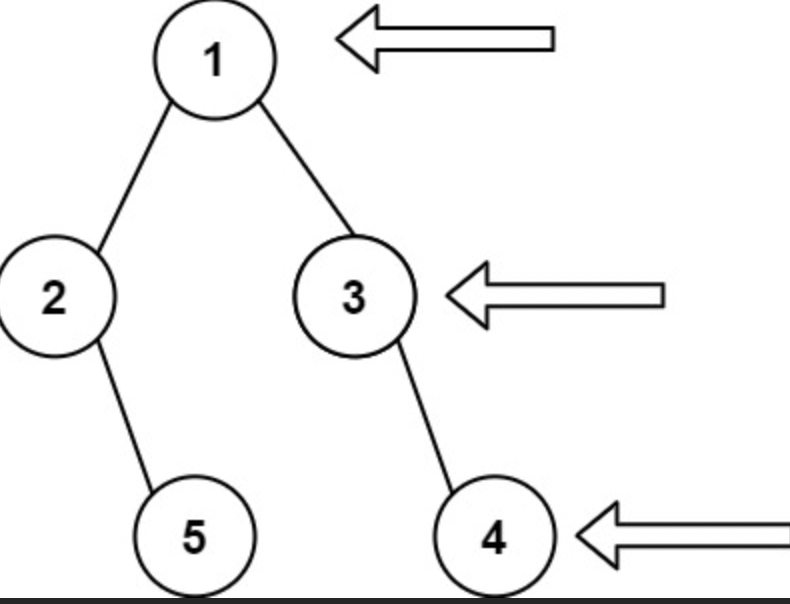
Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]
이 문제는 트리를 오른쪽 측면에서 바라봤을때 가지는 리스트를 구하는 문제입니다. 위의 예시 처럼 오른쪽에서 바라본 노드들의 리스트를 구하게 된다면, 결과는 [1,3,4] 형태의 배열이 나오게 됩니다.
이 문제는 탐색 문제이며 DFS와 BFS의 탐색의 차이점은 결국 쓰임새 즉 용도에 있습니다. BFS는 경로 탐색 중 최적의 조건을 만족하는 경로를 탐색하는데 주로 사용되고 DFS는 최적의 조건 보단 시작점과 목적지의 경로에 대한 결과를 도출하는데 주로 사용되게 됩니다.
결론적으로 이 문제는 DFS 와 BFS 문제로 풀이가 가능합니다. 이 문제는 최적의 조건을 탐색하는 문제이기 때문에 BFS라고 볼 수 있지만 다순 오른쪽 측면에서 바라보는 값에 대한 결과라면 DFS를 통해 풀이가 가능합니다.
왜 그런지 알고리즘 코드를 통해 파악해보겠습니다.
DFS 알고리즘 풀이
class Solution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> rootList = new ArrayList<>();
if(root == null)
return new ArrayList<>();
checkRightSize(rootList, root, 0);
return rootList;
}
public void checkRightSize(List<Integer> list, TreeNode root, int dept) {
if(root == null)
return ;
//깊이레벨과 현재 리스트 길이를 비교하여 동일할 경우 담습니다.
//이 조건을 준 이유는 오른쪽 측면 경로만큼만 줘야하기 때문에 리스트 길이와 동일하게 맞춰줘야 합니다.
if(dept == list.size()) {
list.add(root.val);
}
//DFS일 경우 오른쪽 측면에서 바라본 값이 나와야하기에 우선 오른쪽에 대한
//깊이 우선 탐색을 진행하여 결과를 도출합니다.
checkRightSize(list, root.right, dept+1);
checkRightSize(list, root.left, dept+1);
}
}
위 문제는 DFS문제를 이용하여 풀이한 방식입니다. checkRightSize 메소드를 보게 된다면, List<Integer> 배열에 담는 조건은 리스트의 길이와 깊이 레벨과 동일할 경우에만 리스트에 담을 수 있도록 하였습니다. 이 조건을 만족하기 위해서는 위 문제의 조건인 오른쪽에서 바라본다는 조건이 있기에 가능합니다. 그리고 이 조건을 최종적으로 만족하기 위해서는 반드시 오른쪽 부터 탐색을 재귀함수의 시작으로 두어야한다는 것입니다.
그래서 위의 checkRightSize의 재귀함수를 호출하는 방식을 보면 root.right를 우선 호출하여 오른쪽 측면에 대한 길이 값을 만족합니다.
그렇게 될 경우 오른쪽에서 왼쪽으로 깊이우선탐색을 하기 때문에 오른쪽 노드가 완료되고 왼쪽 노드로 넘어가는 시점에 이미 깊이 레벨과 리스트 레벨이 달라지기 때문에 오른쪽에 대한 리스트 정보만을 리턴하게 됩니다.
BFS 알고리즘 풀이
class Solution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> rootList = new ArrayList<>();
if(root == null)
return new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
int len = queue.size();
for(int i = 0 ; i<len; i++) {
//큐에서 poll을 통해 노드 값을 꺼냅니다.
TreeNode r = queue.poll();
//Queue for문을 통해 제일 마지막에 있은 값을 list에 담습니다.
//이는 왼쪽에서 오른쪽으로 탐색을 하는 구조이기에 큐에서 제일 마지막 값과 동일한 시점에
//노드 값을 리스트에 담아줍니다.
if(i == (len - 1)) {
rootList.add(r.val);
}
// 탐색 조건은 왼쪽에서 오른쪽으로 탐색을 하기 때문에
// left부터 조건을 확인하여 큐에 담고 그 다음 오른쪽 노드 값을 담습니다.
if(r.left != null){
queue.offer(r.left);
}
if(r.right != null) {
queue.offer(r.right);
}
}
}
return rootList;
}
}
BFS 방식은 가까운 노드부터 차례대로 확인해가는 탐색 방식입니다. 그렇기 떄문에 위의 큐를 이용하여 근접 노드에 대한 방문을 확인하고 처리하는 방식으로 진행되게 됩니다.
현재 위 문제의 조건이 오른쪽 측면에서 바라본 결과를 도출하는 것이기 때문에 DFS와 다르게 왼쪽에서 오른쪽으로 탐색을하는 형태로 진행을 합니다. 위 리스트에 담는 조건은 큐의 마지막 값과 와 증감 i 와 동일한 경우 리스트에 담고 있습니다. 이는 왼쪽에서 오른쪽으로 스캔을 하기 때문에 오른쪽에 제일 마지막에 담기게되는 구조가 됩니다. 그렇기 떄문에 위와 같은 조건을 만족하는 경우 리스트에 담도록 진행합니다.
그리고 트리구조이기 때문에 root의 왼쪽과 오른쪽 노드에 대한 값을 큐에 담아줘야합니다. 이 또한 순서는 왼쪽 노드값 그 다음 오른쪽 노드값을 담을 수 있도록 진행을 합니다.
- Total
- Today
- Yesterday
- 리눅스
- dfs
- leatcode
- 캐시
- 도커
- centos7
- 개념 이해하기
- 격리수준
- Lock
- spring
- MySQL
- insert
- 네이버 클라우드
- 컨테이너
- 스케줄러
- 정의
- dockerfile
- LocalDate
- 캘린더
- ncp
- Linux
- 알고리즘
- docker
- Quartz
- Java
- Cache
- 권한
- 이미지
- hazelcast
- mybatis
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |